 DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control
DynaMo: In-Domain Dynamics Pretraining for Visuo-Motor Control
New York University
Abstract
Imitation learning has proven to be a powerful tool for training complex visuomotor policies. However, current methods often require hundreds to thousands of expert demonstrations to handle high-dimensional visual observations. A key reason for this poor data efficiency is that visual representations are predominantly either pretrained on out-of-domain data or trained directly through a behavior cloning objective. In this work, we present DynaMo, a new in-domain, self-supervised method for learning visual representations. Given a set of expert demonstrations, we jointly learn a latent inverse dynamics model and a forward dynamics model over a sequence of image embeddings, predicting the next frame in latent space, without augmentations, contrastive sampling, or access to ground truth actions. Importantly, DynaMo does not require any out-of-domain data such as Internet datasets or cross-embodied datasets. On a suite of six simulated and real environments, we show that representations learned with DynaMo significantly improve downstream imitation learning performance over prior self-supervised learning objectives, and pretrained representations. Gains from using DynaMo hold across policy classes such as Behavior Transformer, Diffusion Policy, MLP, and nearest neighbors. Finally, we ablate over key components of DynaMo and measure its impact on downstream policy performance.
Method
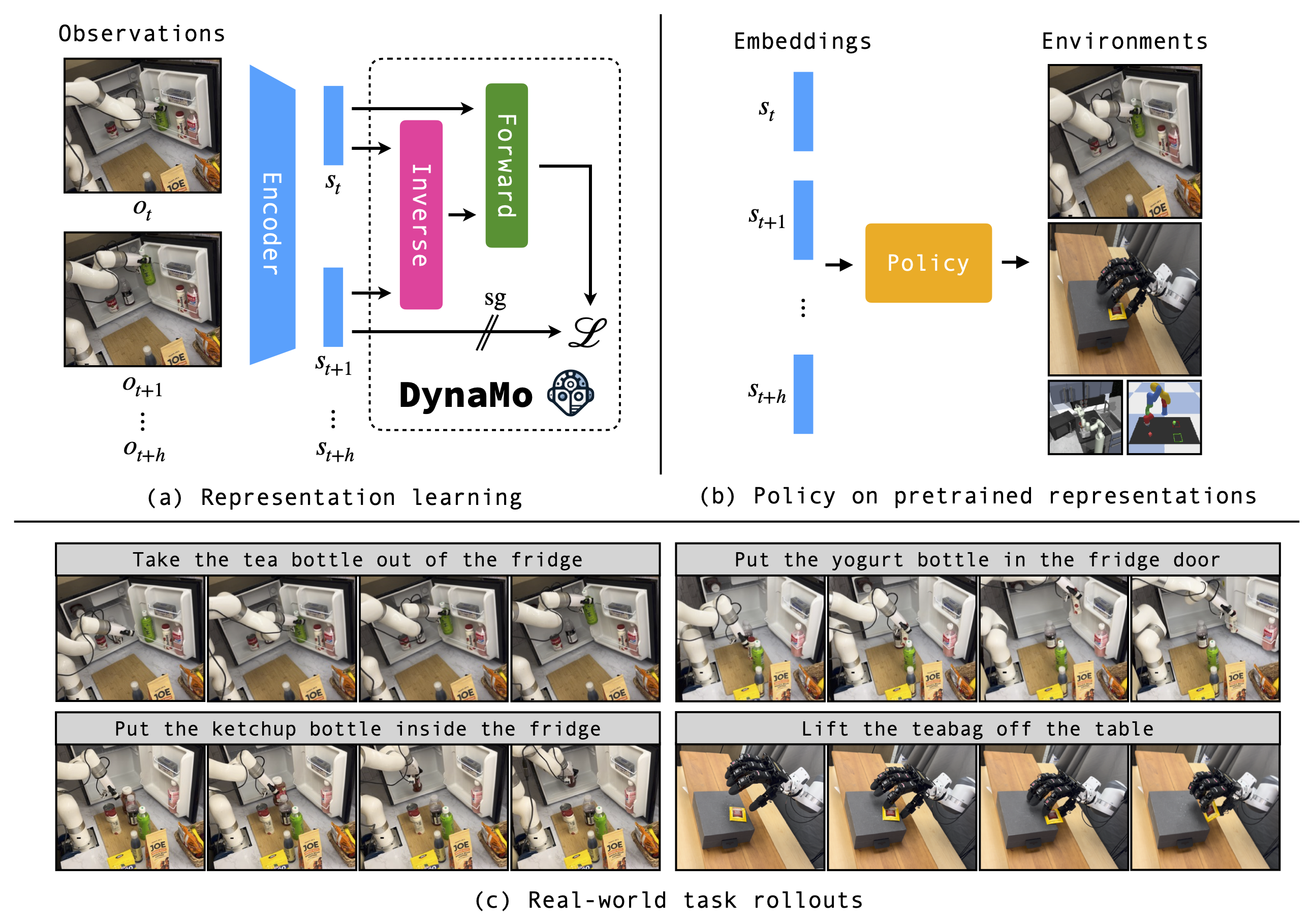
DynaMo, a new self-supervised method for pretraining visual encoders for downstream visuomotor control.
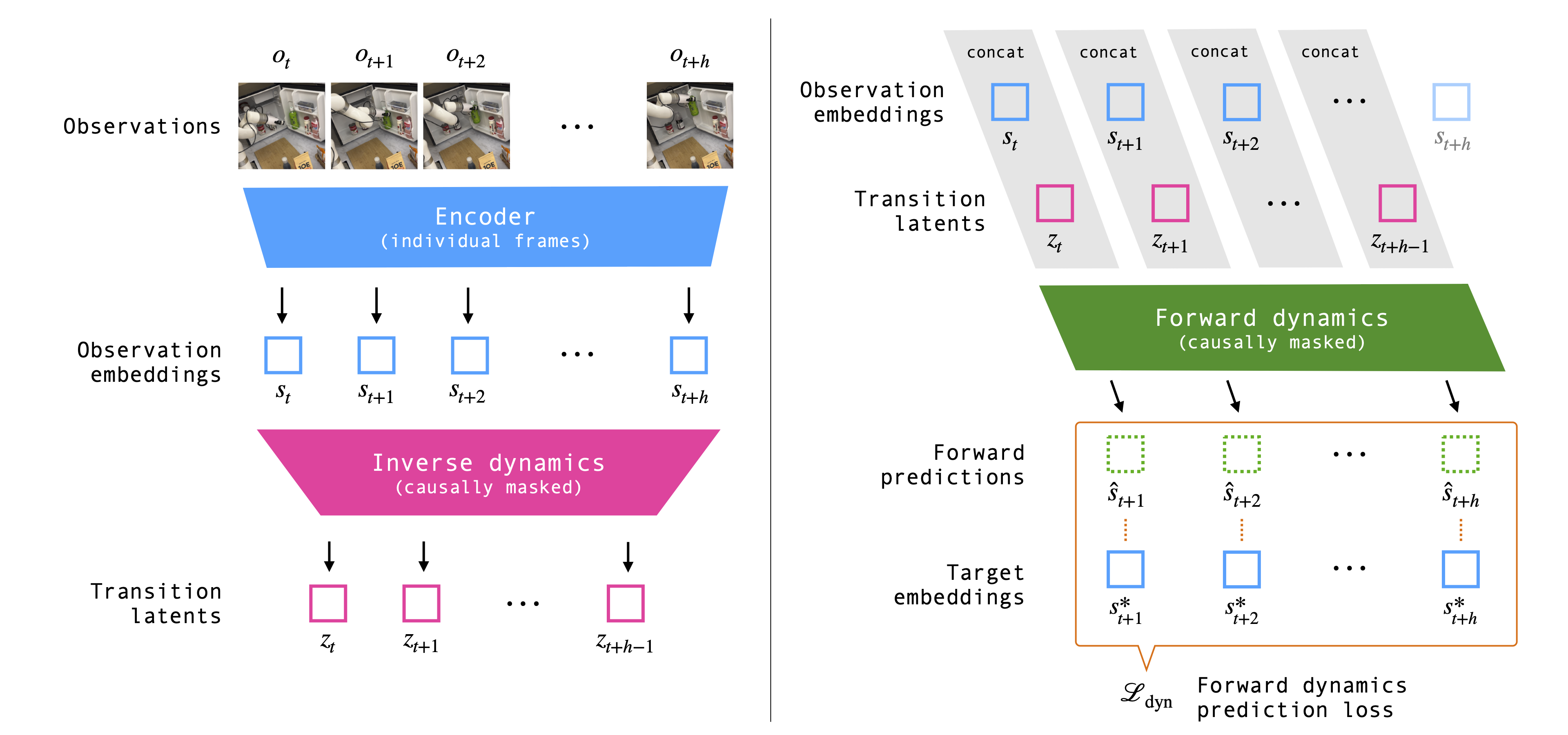
The key insight of our method is that we can learn a good visual representation for control by modeling the dynamics on demonstration observations, without requiring augmentations, contrastive sampling, or access to the ground truth actions. Given a sequence of raw visual observations, we jointly train the encoder, a latent inverse dynamics model, and a forward dynamics model. We model the actions as unobserved latents, and train all models end-to-end with a consistency loss on the forward dynamics prediction. We use a ResNet18 encoder, and causally masked transformer encoders for the inverse and forward dynamics models. The architecture is illustrated below.
Real-world robot rollouts
Rollouts with the DynaMo representation on the Allegro Manipulation environment, and the xArm Kitchen environment. We use a nearest neighbor policy for the Allegro environment, and BAKU with VQ-BeT for the xArm Kitchen environment.
Allegro: pick up the sponge (4x)
Dataset size: 543 frames
Allegro: pick up the teabag (4x)
Dataset size: 1034 frames
Allegro: open the microwave oven (10x)
Dataset size: 735 frames